之前也有看过TCP拥塞控制相关的文章,但是平时没有使用经常就会忘记,也有一部分原因是自己没有对这个没有深刻的理解,导致学了就忘了,所以再复习一下,同时记录下自己对TCP的理解,也希望对TCP拥塞控制不是很熟悉的同学能够带来一些帮助。
滑动窗口和拥塞窗口
先从这两个窗口讲起,滑动窗口有两个作用,一个是为了实现可靠传输,发送端利用滑动窗口来记录已经发送但还未确认的包,还有一个是解决接收端能力不足的问题,假如接收端性能很差,可以通过TCP中的window字段告诉发送端自己还能接收多少数据,这样发送端可以调整发送的数据量从而避免发送过多数据导致接收端处理不过来。
拥塞窗口(cwnd),除了接收端的能力不足,还有可能因为网络的原因导致发送端不能发送太多的数据,如果不加以限制在本来就拥塞的网络路径中狂发包会加剧网络的拥塞。传输网络是大家共享的链路,TCP的拥塞窗口就是用来控制流量,在网络差的时候降低发包量,网络好的时候提高发包量,尽可能公平地利用带宽。
虽然有两个窗口,这两个窗口是一起作用的,实际发送的数据量是取决于这两个窗口的最小值,一般来说滑动窗口的大小会比拥塞窗口大很多,所以发包速率基本上是取决于拥塞窗口。
带宽时延乘积
用个类比的方法来解释这个词,如果把网络比作交通系统,那么TCP就是公路,假设你有个仓库需要负责向一个快递点运输快递,快递点的处理能力有限,一个小时只能处理10辆货车的货,货车从仓库到快递点来回需要半个小时,那么你需要安排多少量车比较合适(假设货车在仓库和快递点的停留时间可以忽略)。如果你比较土豪当然可以安排十辆车每个小时去一次,但是来回时间只要半小时,一小时够货车来回两趟了,所以不需要十辆车,最佳的货车数量 = 来回时间 * 快递点处理速度,半小时 * 10辆/小时 = 5辆,如果货车数量少于5,1小时就不够10辆车到快递点,如果货车数量大于5辆,那么本来一个小时可以跑两趟的车,但是快递点处理速度跟不上导致有的车只能跑一趟,而且安排的车多了还会导致道路更加拥挤。带宽时延乘积就相当于安排的货车数量,这个值是用网络传输最大带宽乘以RTT得到的,也就是一个时刻在网络中飞行(inflight)的数据量,在TCP中就是已经发送出去还未确认的数据量。
拥塞控制算法
如果网络上流动的数据量超出了网络的承载能力就会出现网络拥塞。为了对抗因为流量突发导致丢包,链路上的设备具备缓存让数据包排队,如果网络出现拥塞,那么RTT是会变高的,更严重的时候会因为设备缓冲填满导致丢包。网络拥塞情况有三个阶段:网络畅通(RTT不变)–>网络到达瓶颈,开始拥塞(RTT增大)–>拥塞加剧,过载(出现丢包)。CUBIC是作用在丢包出现的阶段,其实已经出现拥塞了,而BBR则是作用在开始拥塞的阶段。要让网络使用率达到最佳,TCP应该尽量让网络贴着瓶颈在跑,所以TCP拥塞控制算法的目的就是尽量避免网络拥塞情况的出现同时能够高效利用网络传输带宽。
拥塞控制算法是TCP协议的一个主要部分,多年来,通过应用不同的算法,TCP经历了许多改进,最开始TCP只考虑了接收端缓冲溢出的问题而忽略了网络本身的拥塞。在互联网出现了一系列的“拥塞奔溃”问题后在1988年首次引入了拥塞避免的概念。标准的TCP拥塞控制是基于加性增乘性减(AIMD)的算法,该算法包含四个阶段:慢启动、拥塞避免、快速重传和快速恢复。
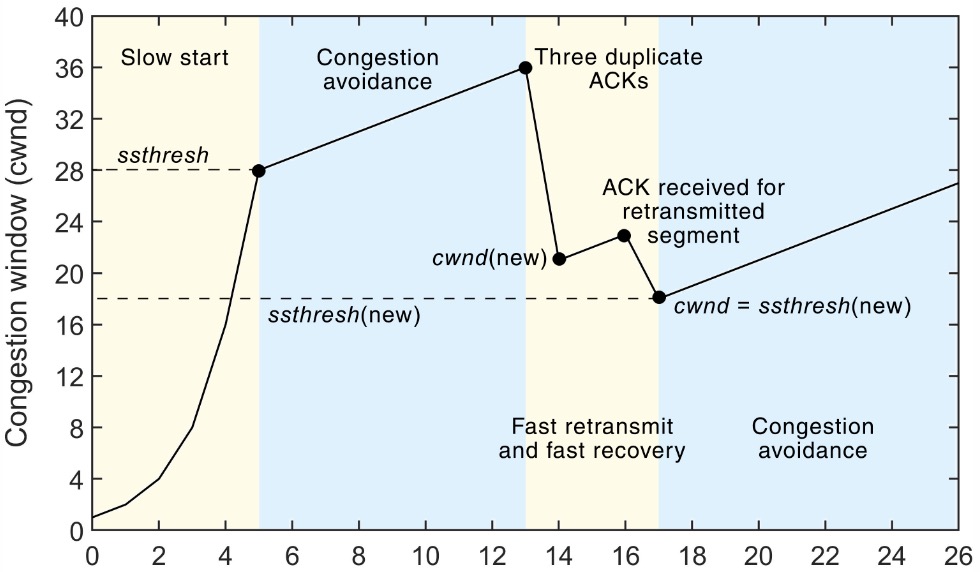 上图展示了TCP拥塞控制的四个阶段:
上图展示了TCP拥塞控制的四个阶段:
- 慢启动
TCP刚开始不知道网络的能力,所以刚开始要逐步增加cwnd,避免一开始发大量的包造成拥塞- 每当收到一个ACK时cwnd++
- 每当经过一个RTT,cwnd *= 2,指数增加
- 为了避免增加过快,还有一个慢启动阈值(ssthresh),当cwnd到达这个阈值之后就进入了拥塞避免阶段,TCP开始小心尝试
- 拥塞避免
上面提到慢启动阶段有个阈值ssthresh,开始时这个阈值一般是65535,cwnd >= ssthresh后就开始拥塞避免- 每收到一个ACK时,cwnd += 1/cwnd
- 每经过一个RTT后,cwnd += 1
- 快速重传和快速恢复
为了避免由于RTO超时时间带来的长时间等待,引入了快速重传机制。快速重传和快速恢复不是回了取代超时重传而是和超时重传搭配使用,一般网络状况特别差时会出现超时重传,并且重新进入慢启动阶段。当接收端接收到的包不连续时,接收端会发送三个冗余ACK触发快速重传,触发快速重传时:- ssthresh = cwnd / 2
- 重传丢失的包
- cwnd = ssthresh + 3
- 如果再收到冗余ACK,cwnd++
- 如果收到新的ACK,cwnd = ssthresh,进入拥塞避免阶段
前面提到的这些是TCP拥塞控制的标准实现,不同的拥塞控制算法可能会不一样,由于拥塞控制在互联网上的研究很多,在过去的几十年里出现了许多的拥塞控制算法。拥塞控制算法重点在于不同场景下权衡不同指标,用于评估拥塞控制算法的主要指标有:吞吐量、延迟、丢包率、公平性和鲁棒性。到目前为止,TCP的拥塞控制算法可以分为三类:(1)以丢包作为拥塞依据的算法(2)测量RTT,以延迟作为拥塞依据的算法(3)丢包和延迟同时参考的算法;下图列举了这几类的拥塞控制算法:
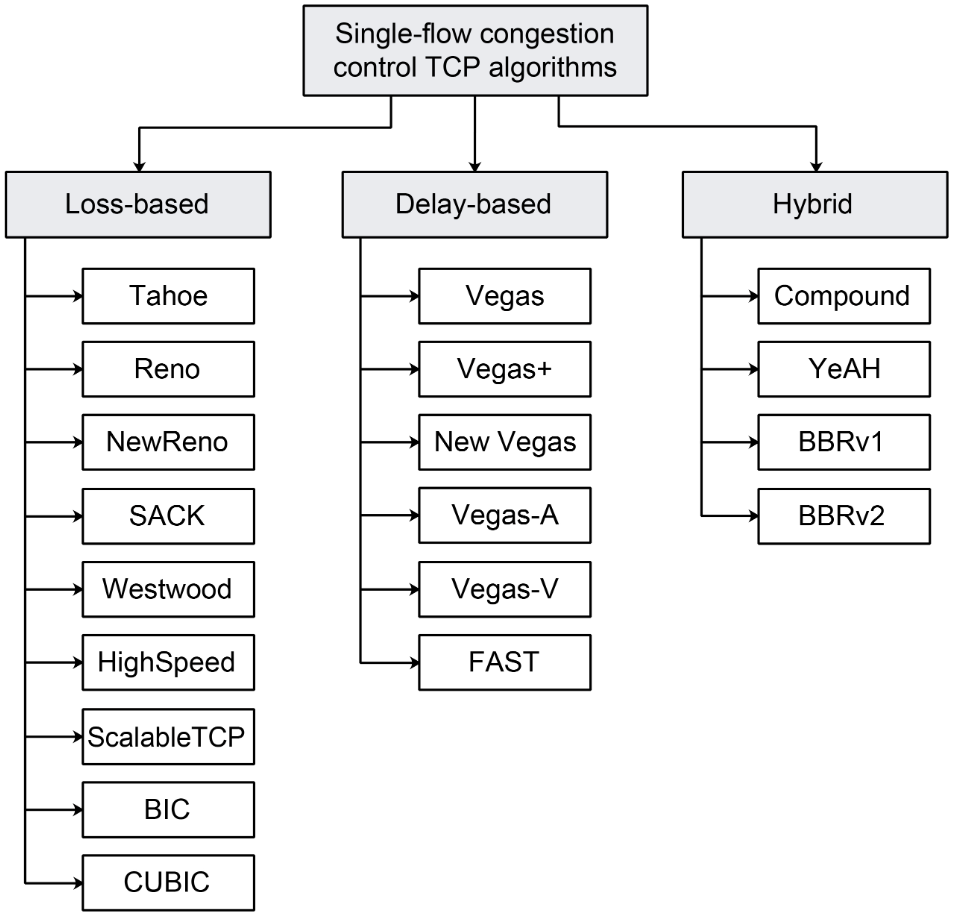
TCP的公平性
在网络传输中往往是多个TCP连接共用一个链路带宽,有些拥塞控制算法会比其他算法争抢到更多的共享带宽,因此确保连接的公平性也是TCP拥塞控制算法需要实现的重要特性。
一般来说,基于丢包的拥塞控制(比如Reno)相比于基于延迟的拥塞控制算法(比如Vegas)更有竞争力,在一条链路上同时存在基于丢包和基于延时的拥塞控制算法时不能公平地分享带宽,因为基于丢包的算法直到出现丢包才会降低速率,而基于延时的算法在丢包出现之前就降低了发送速率,所以基于丢包的算法能够占据更多的带宽。互联网上主流的算法(比如CUBIC和BBR)也有公平性的问题,在链路缓冲比较小的情况下BBR能够比CUBIC获得更多的带宽,相反在链路缓冲比较大时CUBIC更具优势[3]。
参考
- https://encyclopedia.pub/entry/12206
- https://coolshell.cn/articles/11609.html
- Hock, M.; Bless, R.; Zitterbart, M. Experimental Evaluation of BBR Congestion Control. In Proceedings of the IEEE 25th International Conference on Network Protocols (ICNP), Toronto, ON, Canada, 10–13 October 2017.